
GoogleスプレッドシートのIMPORTXML関数を使うと
HTMLのページの中から、指定の場所のデータを
スプレッドシートにインポートすることが可能です。
他にも、XML・CSV・RSSフィード・TSV
Atom XML フィードなども可能です。
この記事ではその方法を書いていきます。
IMPORTXMLの数式
IMPORTXML関数は下記のように書きます。
IMPORTXML(“ページURL”,”XPath”)
ページURL
データを取り出したいページのURL
XPath
取り出したいデータのXPathクエリ。
XPathの調べ方
XPathの調べ方は簡単です。
この記事では、Googlechromeを使っていきます。
データを取得したい場所を選択した状態で、
右クリック⇒ 検証をクリック。
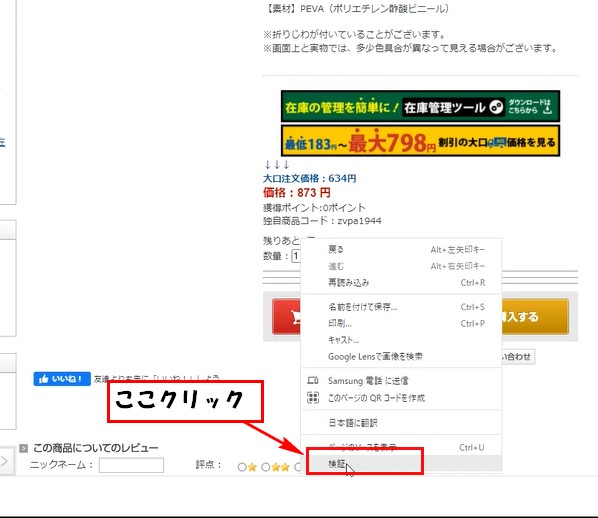
今回は在庫数のデータを取得するやり方で説明します。
デベロッパーツールが表示されます。
上部の□マークの所を選択した状態で、再度データを
取得したい場所にカーソルを合わせてクリックします。
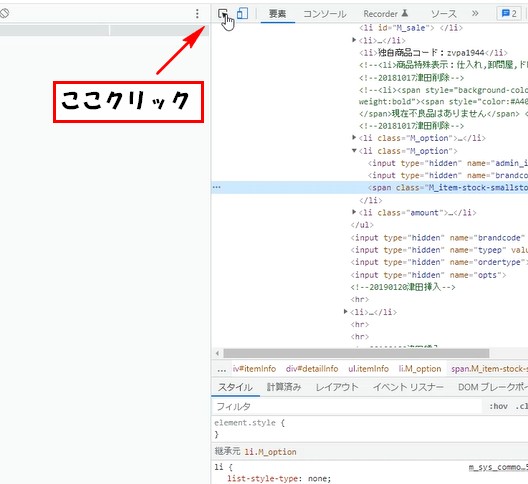
するとデベロッパーツールの該当箇所に青い線が
表示されます。
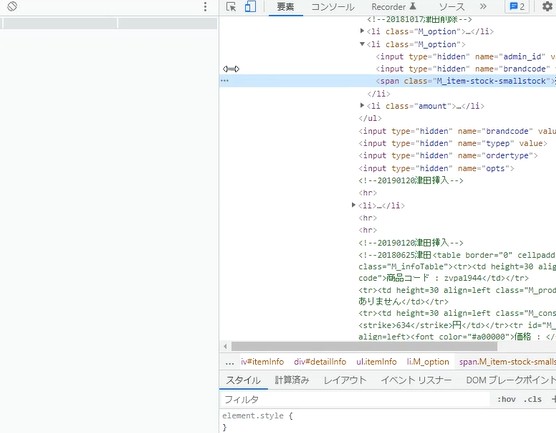
左端の点の部分を右クリック。
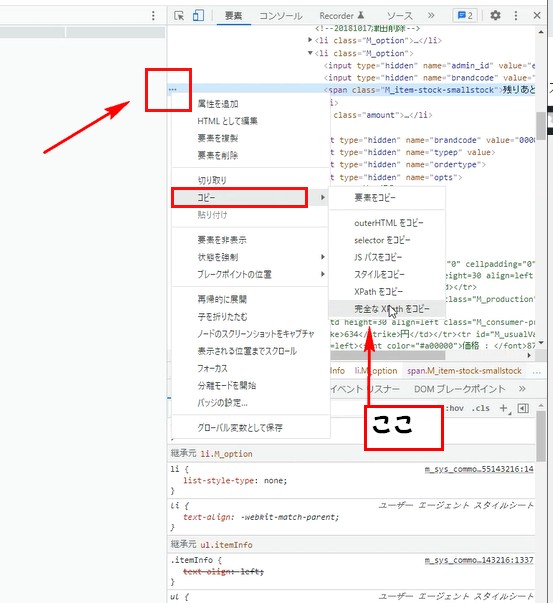
コピー⇒ XPathをコピーか完全なXPathをコピーの
どっちかをクリックで、コピー出来ます。
そのまま、関数に貼り付けます。
これで、XPathの取得が完了。
XPathをコピーで取得した値
//*[@id=”detailInfo”]/ul/li[6]/span
完全なXPathをコピーで取得した値
/html/body/center/center/div/div[2]/table/tbody/tr[1]/td[3]/form[2]/div/div/div[2]/div[2]/ul/li[6]/span
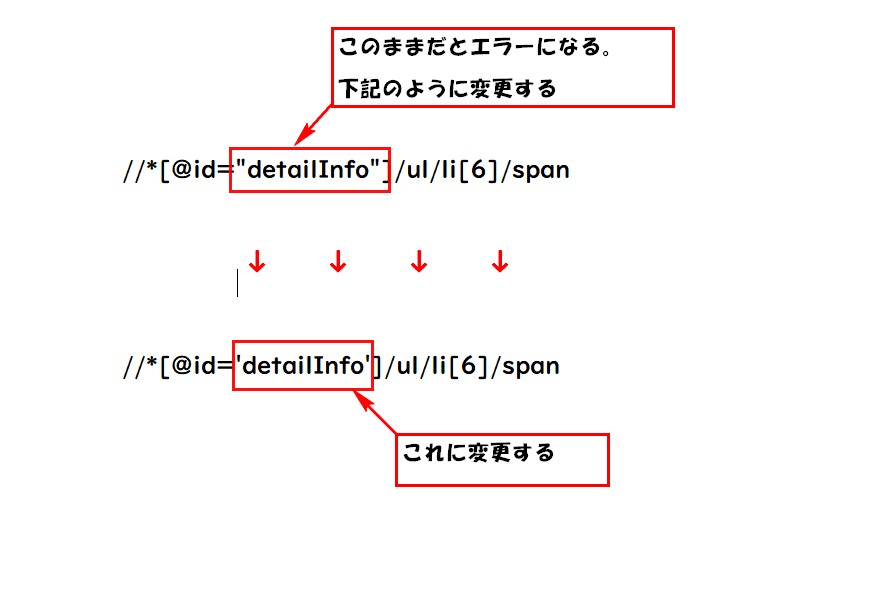
XPathをコピーで取得した値を記入する場合の注意。
真中に、ダブルクォーテーションで囲まれた部分があります。
今回の場合は、“detailInfo”になります。
このままだとエラーになります。
この部分を、シングルクォーテーションに変更するとOKです。
‘detailInfo’ に変更すると大丈夫。
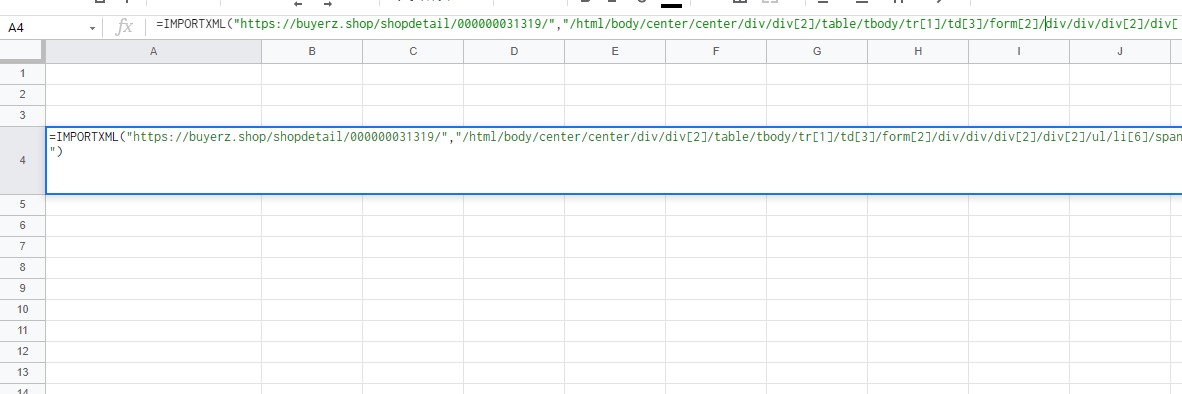
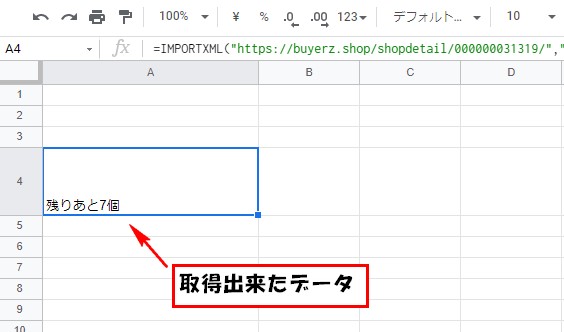
Googleスプレッドシートの関数の所に、
URLとXPathを記入して、データの取得が可能になりました。
IMPORTXML関数使ってみて
このIMPORTXML関数は、大手のサイトでは使えません。
ちょっとしたデータの取得には便利ですが、
データ取得の精度はあまりいい感じではなかったです。
また、データ収集には重たい感じなので、多くのデータ取得
には使用できない感じです。
使用するには注意が必要になります。
また、スクレイピングを行う場合は、最新の注意で行いましょう。


コメント